Model Training
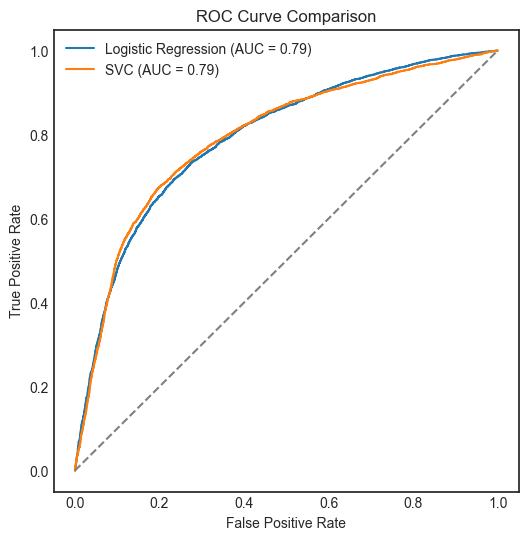
Four machine learning models were trained and evaluated using confusion matrix and ROC curve: Logistic Regression, Support Vector Classifier, Gradient Boosting Classifier, and XGBoost Classifier.
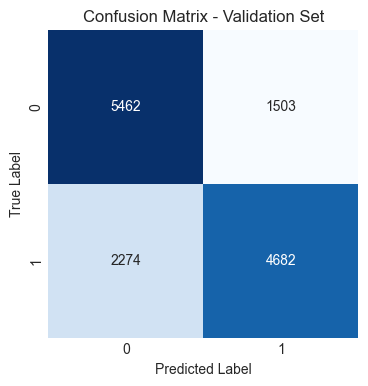
Model parameters: (penalty='l1', solver='saga', max_iter=10000, random_state=42)
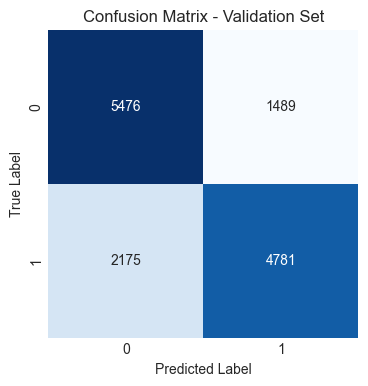
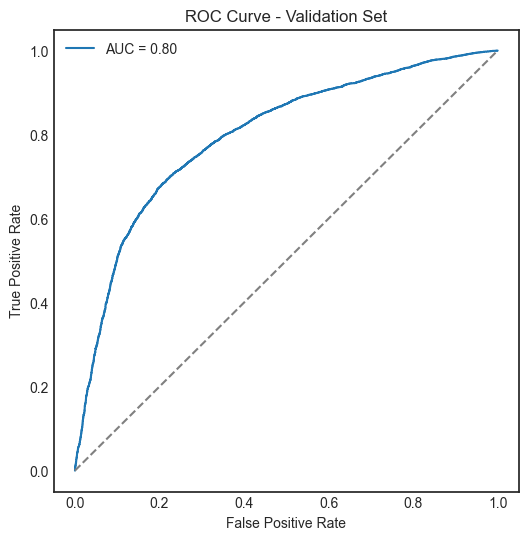
Model parameters: (kernel='rbf', C=100, gamma=.01, random_state=42)
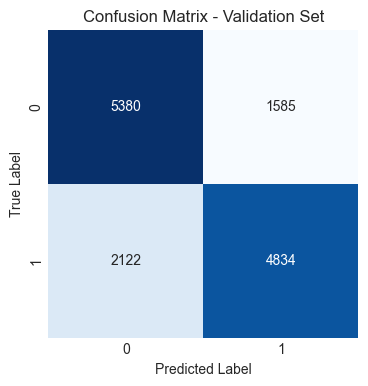
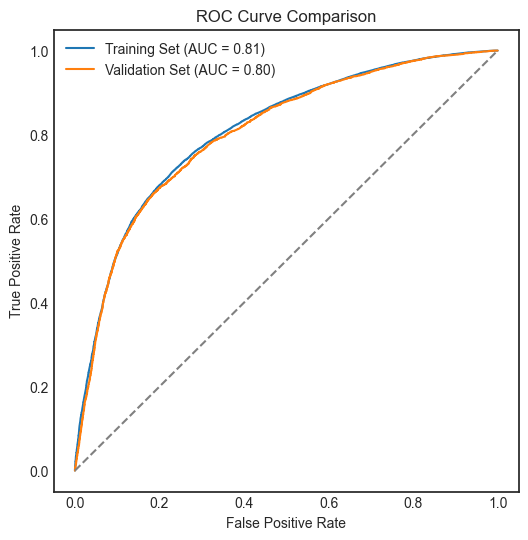
Model parameters: (learning_rate=0.1, n_estimators=100, max_leaf_nodes=16, random_state=42)
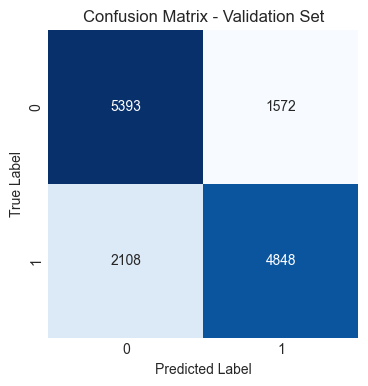
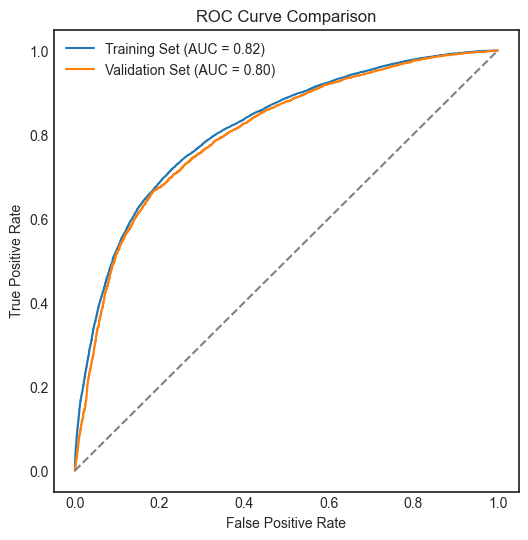
Model parameters: (objective='binary:logistic', seed=42, subsample=.75, gamma=.5, learning_rate=.05, max_depth=5, random_state=42)
Support Vector Classifier (SVC), Gradient Boosting Classifier, and XGBoost Classifier performed similarly and slightly better than Logistic Regression.
To explore the SVC in action, Principal Component Analysis (PCA) was used for reducing the dimensionality of the feature space into two components to visualise the classification results.
Additionally, a single decision tree was trained to visualise the decision-making process of a tree-based model.
Principal Component Analysis (PCA)
Principal Component Analysis (PCA) is useful to exploit the variance especially in high-dimensional dataset. It is a linear transformation technique that transforms the original features into a new set of uncorrelated features called principal components. The first principal component captures the most variance in the data, while the second captures the second most, and so on. By reducing the dimensionality of the feature space to two components, we can visualise the classification results of the Support Vector Classifier (SVC) in a two-dimensional plot. This allows us to see how well the SVC separates the classes based on the transformed features, providing insights into the model's performance and decision boundaries.
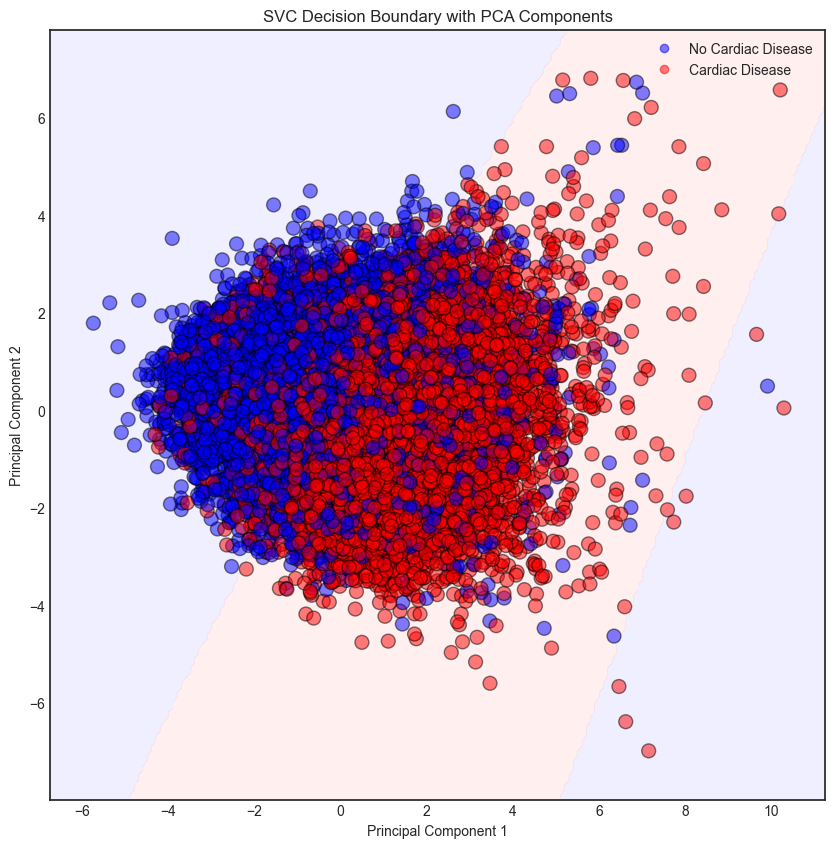
When the feature space is reduced to two dimensions, the decision boundaries of the SVC become more apparent, allowing for a better understanding of how the model makes predictions. In the current model, a default Gaussian kernel was used which measures the similarity between data points in the transformed feature space. As the above classification boundary plot shown, the model managed to correctly classified most of the data points. However, there are apparently many misclassifications. The classification may require higher dimensional feature space for better performance.
Decision-Making Process in a Single-Tree Model
To visualise the decision-making process of a tree-based model, a single decision tree was trained on the dataset. The decision tree is a flowchart-like structure where each internal node represents a feature, each branch represents a decision rule, and each leaf node represents an outcome (class label). By examining the structure of the decision tree, we can understand which features are most important for making predictions and how the model arrives at its decisions. The tree's splits indicate the thresholds for different features that lead to different classifications, providing insights into the relationships between features and the target variable.
The visualisation of the decision tree reveals the decision-making process of the model, which can be manually traced from the root node to the leaf nodes. Each split in the tree represents a decision based on a specific feature and its threshold value.